Projects
SLAPMAN
Streaming LAnguage Processing in MANufacturing
Start: 07/2020
End: 06/2021
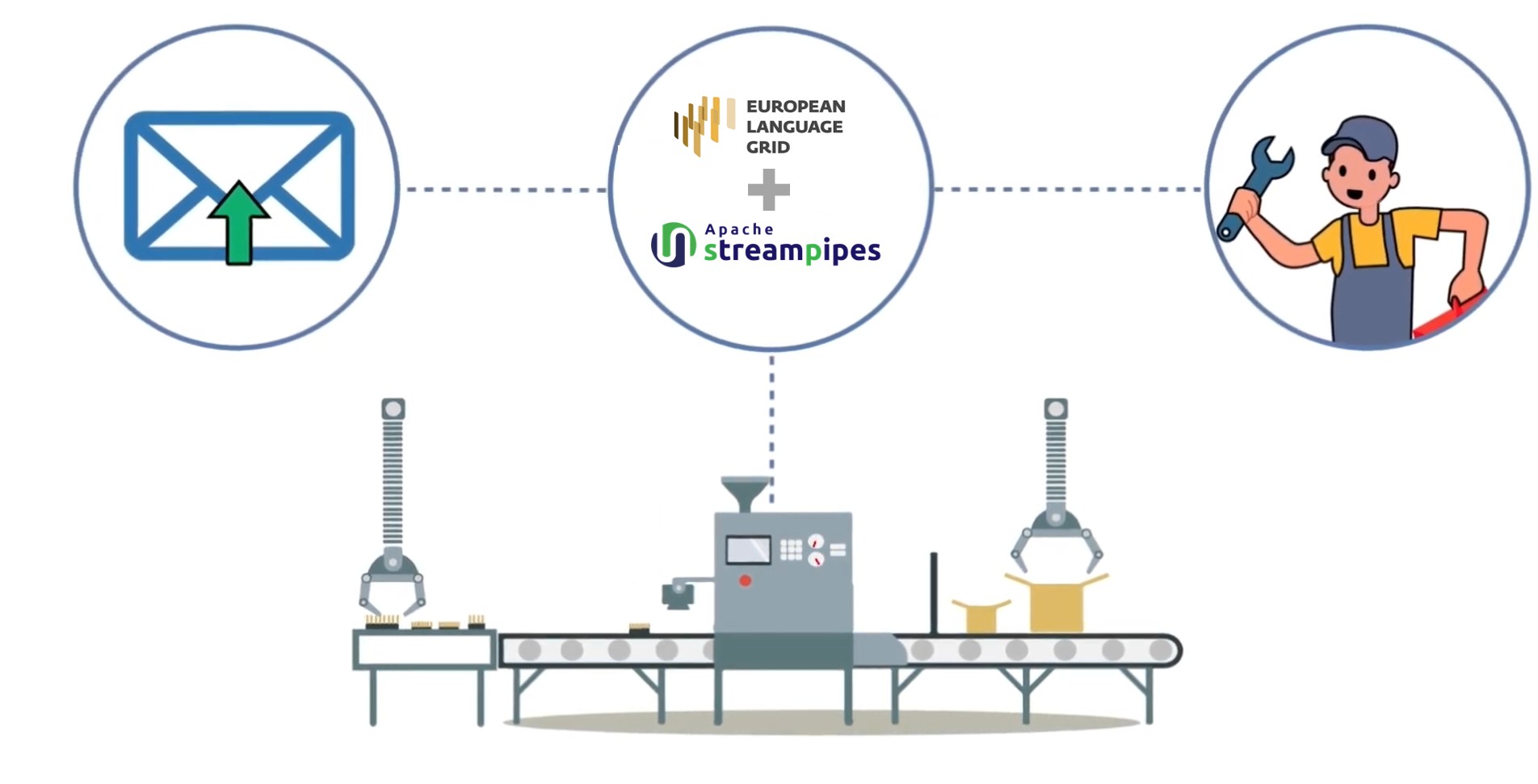
SLAPMAN develops and integrates streaming language technology modules for processing, analyzing, and exploiting unstructured or semi-structured process data from manufacturing. These include adapters for textual data sources, such as production plans from MES systems, machine status data, or error logs, as well as pipeline elements for natural language processing. Planned functionalities include tokenization, language detection, domain-specific named entity recognition, word embeddings, translation, and the enrichment of natural-language input. A particular focus is placed on a learning component that can quickly adapt existing models to new machines, processes, or domain-specific text corpora using few-shot learning. The components are implemented as standalone microservices, made available as plugins in Apache StreamPipes, and can be combined into analytics pipelines via a graphical user interface. For integration into the European Language Grid, the modules are provided as cloud-native, Kubernetes-compatible services using Helm charts.
Role of the FZI
In the project, FZI applies its expertise in stream processing, data management, knowledge engineering, and machine learning. Since Apache StreamPipes was originally developed at FZI, FZI is particularly well-positioned to extend the platform with language processing capabilities for industrial use cases. FZI's tasks include requirements analysis with the ELG community, the development of adapters for industrial text and log data, the implementation of NLP microservices, the development of the domain-specific learning component, and the integration of the results into Apache StreamPipes and the ELG infrastructure.
More information
Contact person

Department Manager
Division: Information Process Engineering
Headquarters Karlsruhe
Research focus
Applied Artificial Intelligence
AI from research to practice: We promote applied AI for business and small and medium-sized enterprises, integrating technology with law and ethics.
Energy and Sustainability
Sustainability and practical relevance are key: We develop IT innovations for companies that contribute to a climate-friendly and resource-efficient economy.
Funding notice:
Funded by European Language Grid, Pilot Project / First ELG Open Call; ELG received funding from the European Union’s Horizon 2020 programme.