Projekte
SLAPMAN
Streaming LAnguage Processing in MANufacturing
Start: 07.2020
Ende: 06.2021
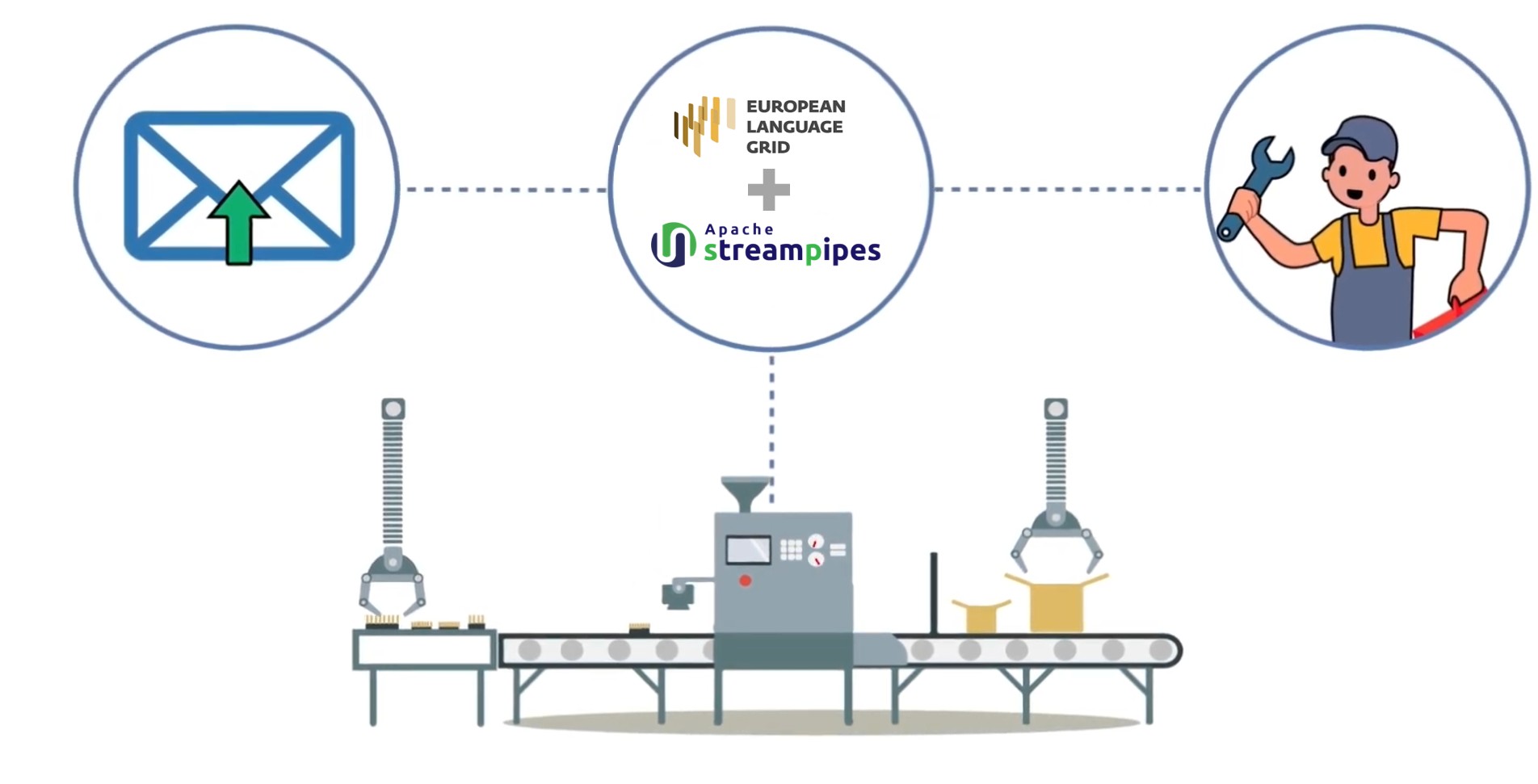
SLAPMAN entwickelt und integriert Streaming-Language-Technology-Module zur Verarbeitung, Analyse und Nutzung unstrukturierter oder semi-strukturierter Prozessdaten aus der Fertigung. Dazu gehören Adapter für textuelle Datenquellen, beispielsweise Produktionspläne aus MES-Systemen, Maschinenstatusdaten oder Fehlerlogs, sowie Pipeline-Elemente für Natural Language Processing. Vorgesehen sind unter anderem Tokenisierung, Sprachdetektion, domänenspezifische Named Entity Recognition, Word Embeddings, Übersetzung und Anreicherung natürlicher Spracheingaben. Ein besonderer Fokus liegt auf einer Lernkomponente, die vorhandene Modelle mithilfe von Few-Shot-Learning schnell an neue Anlagen, Prozesse oder domänenspezifische Textbestände anpassen kann. Die Komponenten werden als eigenständige Microservices umgesetzt, in Apache StreamPipes als Plugins verfügbar gemacht und über eine grafische Oberfläche zu Analysepipelines kombinierbar. Für die Integration in das European Language Grid werden die Module cloud-nativ, Kubernetes-kompatibel und über Helm Charts bereitgestellt.
Rolle des FZI
Im Projekt nutzt das FZI seine Expertise in Stream Processing, Datenmanagement, Knowledge Engineering und maschinellem Lernen. Da Apache StreamPipes ursprünglich am FZI entwickelt wurde, kann das FZI insbesondere die Erweiterung der Plattform um Sprachverarbeitungsfunktionen für industrielle Anwendungsfälle, leicht umsetzen. Zu den Aufgaben gehören die Anforderungsanalyse mit der ELG-Community, die Entwicklung von Adaptern für industrielle Text- und Logdaten, die Umsetzung von NLP-Microservices, die Entwicklung der domänenspezifischen Lernkomponente sowie die Integration der Ergebnisse in Apache StreamPipes und in die ELG-Infrastruktur.
Weitere Informationen
Ansprechperson

Abteilungsleiter
Bereich: Information Process Engineering
Hauptsitz Karlsruhe
Forschungsschwerpunkte
Angewandte Künstliche Intelligenz
KI aus der Forschung in die Praxis: Wir treiben angewandte KI für Wirtschaft und Mittelstand voran und verbinden dabei Technologie mit Recht und Ethik.
Energie und Nachhaltigkeit
Nachhaltigkeit und Praxisnähe zählen: Wir entwickeln IT-Innovationen für Unternehmen, die zu einer klimafreundlichen und ressourceneffizienten Wirtschaft beitragen.
Förderhinweis:
Gefördert durch European Language Grid, Pilot Project / First ELG Open Call; ELG wurde durch das EU-Programm Horizon 2020 gefördert.